
What I want to do is build a model for sequence-to-sequence type prediction on the Dow Jones Industrial Average (DJI). However, rather than treat this as a regression problem, I want to discretize the problem, so that what I am predicting is one of a set number of possible “types” of predictions. Using SAX and PAA, I can take the closing prices of the DJI on 50 consecutive days. I do this by using PAA to reduce the window of 50 points to 3 points, and use the letters ‘a’ and ‘b’ (below mean, above mean) to describe this windows as a three letter word such as ‘aab’ or ‘aba’. Since I am only using ‘a’ and ‘b’, I have 8 possibilities, though only 6 show up in the data (from 1970–present). Here’s how I did this: first, I used the nolitsa library to do some simple moving average smoothing on the data. Then I created the 50 time step windows with a stride of 1 (so lots of overlapping) using the pyentrp. Finally, I used saxpy to do PAA (reducing 50 to 3) and then SAX to create symbolic representation using 2 letters.
Data can be found in the the Kaggle competition: DJIA 30 Stock Time Series
import numpy as np
from pyentrp import entropy as ent
from saxpy.znorm import znorm
from saxpy.paa import paa
from saxpy.sax import ts_to_string
from saxpy.alphabet import cuts_for_asize
words = []
dow_df = ent.util_pattern_space(hist_sma, lag = 1, dim = 50)
dow_df = dow_df[:]
for i in range(len(dow_df)):
dat_znorm = znorm(dow_df[i,:])
dat_paa= paa(dat_znorm, 3) #three letter words
word = ts_to_string(dat_paa, cuts_for_asize(2)) # 2 let alphabet
words.append(word)
Symbolic Aggregate Approximation (SAX) is a way of discretizing a time series so that it can be represented with a sequence of alphabetical letters, forming a “word”. Piecewise Aggregate Approximation (PAA) shortens the time series.
I used a standard Bidirectional LSTM with one layer and then a Dense/Softmax layer and a sequence of anything from 3–10 timesteps to make the prediction of the next step.
model = Sequential()
model.add(Bidirectional(LSTM(32, kernel_initializer = "he_normal",return_sequences=False),
input_shape=(n_timesteps, output)))
#model.add(Bidirectional(LSTM(32, return_sequences = False)))
model.add(Dense(output, activation='softmax'))
model.summary()
model.compile(loss='categorical_crossentropy', optimizer=Adam(lr=.001), metrics=['acc'])
With early stopping, you can get around 84% F1-score, so that’s not too bad, though the sequence itself is not that varied. Of the 6 “labels” you will find that it stays this way for quite a number of steps (at least more than 10) before changing into another label. When you look at the predictions and the ground-truth, you will find that the transitions are always off — that’s where the model makes a bunch of mistakes. It tends to “figure out” the change 1 or 2 steps after it happens in ground-truth.
Next, I decided to use the tslearn package to cluster the 50 time step windows; using the Euclidean metric (the fastest one by a long shot). I wanted to see what I would get if I demanded 6 clusters.
km = TimeSeriesKMeans(n_clusters=6,verbose=True, random_state=seed)
y_pred = km.fit_predict(df)
This is what came out:
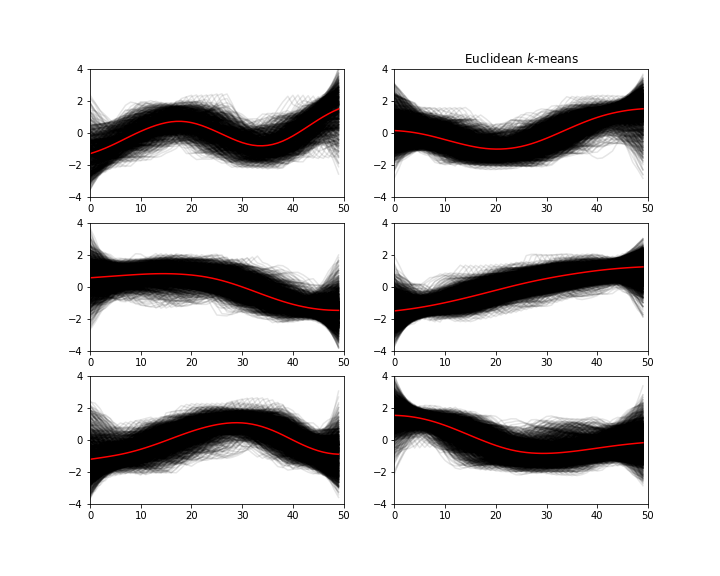
There is some level of resemblance between the ‘words’ and the ‘clusters’. If you were just dealing with clusters; you could either train a model to learn the sequence of clusters, or else just create a classification model that takes maybe 20–30 points of your current window, and classify with one of the 6 labels so that you had some idea of where it might go in the near future. Lastly, I’ll just say that it would be interesting to see what would happen if you either wanted more clusters or if you changed the time period…and also what would happen if you used a stride > 1, thereby downsampling and using less of the data. Maybe some other time.
Conclusion
The Deep Learning models are very powerful solutions to a wide range of Data Science projects. However, even these powerful solutions can't show good results if used naively and without additional efforts to make a proper preparation of the data. The more work we spend to help our models, the better results they will show.
References
https://machinelearningmastery.com/develop-bidirectional-lstm-sequence-classification-python-keras/
Go Top
comments powered by Disqus